Die Impressumspflicht zwingt quasi jeden Betreiber einer Webseite ein Impressum einzubinden. Hier müssen einige persönliche Informationen angegeben werden, was im Internet auch schnell mal missbraucht wird. So ist schon lange bekannt, dass sogenannte Harvester durch einfaches parsen von Webseiten unter anderem E-Mail-Adressen sammeln, die dann für den Spamversand genutzt werden. Aus diesem Grund wurden schon viele Methoden entwickelt, um das einfache Auslesen der E-Mail-Adresse zu verhindern. Einige basieren auf der Manipulation der Anzeige über CSS oder Javascript, da die Harvester, zumindest bis heute, nur den html-Quelltext der Webseiten durchsuchen ohne Javascript und CSS zu interpretieren. Einen interessantes Projekt in diesem Zusammenhang findet man hier: http://www.drweb.de/magazin/wirklich-wirksamer-schutz-fr-e-mail-adressen/
Doch in diesem Artikel möchte ich mich mit einem anderen Schutzmechanismus beschäftigen. Mit der Verwendung von Bildern, auf denen die E-Mail-Adresse geschrieben steht, sollen Harvester ausgetrickst werden, da sie den Text nicht lesen können. Oder etwa doch?
Da ich in mehreren Projekten bereits mit OCR (Abkürzung für: Optical Charater Recognition) in Berührung gekommen bin, also dem computergestützten Erkennen von Schrift in Bilddateien, stellte ich mir die Frage wie sicher diese E-Mail-Bilder wirklich sind. Einem entsprechend programmierten Harvester sollte es doch möglich sein den Text auf den Bilddateien zu erkennen und somit die E-Mail-Adresse zu ermitteln.
Aus der Neugier heraus, ob das wirklich funktioniert, habe ich hierfür ein Testprogramm als Proof-Of-Concept geschrieben. Die Basis für die Erkennung sind 30 selbst erstellte E-Mail-Bilder, die ich mittels verschiedener Onlinedienste erzeugt habe. Um ein möglichst realistätsnahes Ergebnis zu erhalten, habe ich außerdem mehrere übliche Variationen beim Erzeugen angewendet.

service_1_0

service_1_1

service_1_2

service_2_0_0
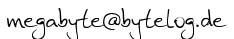
service_2_0_1

service_2_0_2

service_2_1_0
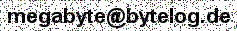
service_2_1_1
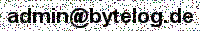
service_2_1_2
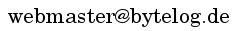
service_2_2_0

service_2_2_1
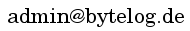
service_2_2_2

service_3_0

service_3_1

service_3_2

service_4_0

service_4_1

service_4_2

service_5_0

service_5_1

service_5_2

service_6_0_0

service_6_0_1

service_6_0_2

service_6_1_0

service_6_1_1
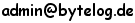
service_6_1_2

service_7_0

service_7_1

service_7_2
Der Programmablauf ist dabei wie folgt:
- Optimieren der Bilder für die OCR - Da eine OCR meist für die Erkennung von Text auf gescannten Dokumenten optimiert ist, hat diese bestimmte Anforderungen an das Quellmaterial. Die hier verwendeten E-Mail-Bilder wurden deshalb vor der Texterkennung optimiert, um bessere Ergebnisse zu erhalten. Nach vielen Versuchen bin ich bei folgendem Algorithmus angekommen: Bild in Graustufen umzuwandeln, skalieren und dann den Kontrast erhöhen. Ein interessanter Effekt hierbei ist, dass sich dadurch nicht nur die Erkennungsqoute gegenüber dem unbearbeiteten Bild verbessert hat, sondern auch die Verarbeitungsgeschwindigkeit der OCR deutlich erhöht wurde.
- Auslesen der E-Mail-Adresse aus den Bildern - Da ich es auch schon in anderen Projekten gemacht hatte, lag es nahe die freie OCR-Engine "tesseract" zu verwenden¹. Sie liefert ausreichend gute Ergebnisse, auch wenn die proprietäre Konkurrenz bekanntermaßen bessere Erkennungsraten bietet.
Zum Schluß habe ich das Ergebnis noch manuell kontrolliert, um zu prüfen ob die OCR richtig lag.
Lets go

Programmdurchlauf des EMailImageReader
Nun sollen endlich ein paar Zahlen zu den Ergebnissen folgen, wobei ich mir natürlich bewusst bin, dass die verwendeten Inputbilder keine repräsentative Stichprobe, aber für diesen Test absolut ausreichend sind. Die Verarbeitungszeit der 30 Bilder betrug über mehrere Läufe gemittelt etwa 4,5 Sekunden. Die Erkennungsquote der OCR lag dabei im Durchschnitt bei 33 %. Wenn genügend Inputbilder zur Verfügung stehen ergeben sich daraus 133 korrekt ermittelte E-Mail-Adressen pro Minute, was hochgerechnet fast 8000 E-Mail-Adressen pro Stunde ergibt. Auch wenn klassische Harvester vermutlich eine deutlich größere Leistung durch einfaches Parsen von Webseiten erreichen, ist dies ein beachtlicher Wert.
Wie erwartet war die Erkennung bei Bildern mit sehr speziellen Fonts oder Bildrauschen sehr schlecht. Man muss aber auch anmerken, dass das hier verwendete Programm nur als Proof-Of-Concept bezeichnet werden kann. Es gibt noch einige Möglichkeiten die Erkennungsquote und Performance deutlich zu erhöhen und damit die Anzahl korrekt erkannter E-Mail-Adressen pro Minute.
- Der oben beschriebene Algorithmus zur Bildoptimierung lässt sich zum Beispiel um das Entfernen von Bildrauschen oder eine dynamische Kontrastverbesserung erweitern.
- Die einzelnen Anwendungsschritte lassen sich gut parallelisieren. Durch den Einsatz von Multithreading kann das Suchen und Laden der Bilddateien, die Optimierung der Bilddateien und die OCR gleichzeitig für verschiedene E-Mail-Bilder erfolgen. Die Geschwindigkeit dürfte sich dadurch leicht um den Faktor 5 - 10 erhöhen lassen und ist dann hauptsächlich durch die Systemleistung (CPU für OCR und Internetanbindung wegen Webseiten- und Bilder-Download) beschränkt.
- Durch Optimierung der OCR lässt sich die Erkennungsrate noch deutlich erhöhen. Zum Beispiel ließe sich die OCR trainieren, so dass E-Mail-Adressen besser erkannt werden. Alternativ kann auch eine sogenannte Whitelist angegeben werden, die nur Zeichen enthält, die auch in E-Mail-Adressen zulässig sind. Über ein Wörterbuch, dass die häufigsten E-Mail-Provider-Domains enthält, kann die OCR-Erkennung nochmals deutlich verbessert werden. Man könnte das Wörterbuch sogar beim Crawlen dynamisch um die Domainnamen erweitern, von welchen entsprechende Bildern geladen wurden.
Wie wahrscheinlich ist der Einsatz von OCR bei Harvestern?
Auch wenn es keine technischen Hürden gibt mittels dem hier beschriebenen Verfahren E-Mail-Adressen zu sammeln, gibt es keinen Grund zur Panik. Es ist doch sehr unwahrscheinlich, dass diese Technik von Harvestern verwendet wird, auch in absehbarer Zukunft. Folgende Punkte müssen nämlich bedacht werden:
- Da die OCR-Technologie relativ viel CPU-Leistung benötigt, ist das hier beschriebenene Verfahren deutlich rechen- und somit kostenintesiver als das herkömmliche Parsen von Webseiten.
- Damit ein Crawler möglichst effizient arbeitet, müsste er für die vielen verschiedenen Anbieter und Varianten von E-Mail-Bildern speziell angepasst werden, was einen hohen Aufwand verursacht.
- Manche Anbieter von E-Mail-Bildern bieten die Möglichkeit die Providerdomain als separate Grafik abzubilden (z.B.: @gmail.com) und Textfarben und -größen zu ändern um OCR zur erschwehren. Diese Techniken bieten zwar keinen echten Schutz, empfehle ich aber trotzdem jedem, der auf E-Mail-Bilder nicht verzichten kann oder möchte. Der Aufwand dem Crawler das Erkennen der Grafiken "beizubringen" dürfte auch kaum im Verhältnis zum daraus resultierenden Nutzen stehen.
- Tendenziell werden Personen, die Ihre E-Mail-Adresse mit so viel Aufwand versuchen zu schützen, kaum auf den versendeten Spam "klicken". Die Opferquote dürfte hier viel geringer sein, als unter Personen, deren E-Mail-Adressen unbedarft ins Internet gelangen. Eine teuere Optimierung durchzuführen um danach nicht die primäre Zielgruppe zu erreichen
E-Mail-Bilder sicher nutzen
Auch wenn man vor Lesenden-Harvestern aus oben genannten Gründen keine Angst haben muss, lässt sich der Einsatz von E-Mail-Bildern mit ein paar einfachen Richtlinien weiter absichern:
- Binden Sie das Bild nicht über einen Link zum Hersteller ein, da dieser über das Parsen der Seite Rückschlüsse zulässt. Legen Sie das Bild einfach auf dem eigenen Webspace ab.
- Wenn das Bild über JavaScript / CSS eingebunden wird, kann der Link zum Bild in der Regel nicht durch einfaches Parsen der Webseite ermittelt werden.
- Verwenden Sie keinen Dateinamen, der darauf hinweist, dass auf dem Bild eine E-Mail-Adresse vorhanden ist.
¹ Es ist zwar möglich eine in .NET verwendbare Version von tesseract aus dem Quelltext zu erzeugen allerdings gibt es hierfür auch schon fertige Projekte im Netz, die das Einbinden der OCR deutlich vereinfachen. Ich habe in diesem Fall das Projekt von Charles Weld verwendet: .NET Wrapper für tesseract (GitHub-Link)